
啥?拿下诺奖的AlphaFold团队也解散了
啥?拿下诺奖的AlphaFold团队也解散了据英国《金融时报》7 月 29 日报道,谷歌 DeepMind 已经重组了曾打造诺贝尔奖级成果 AlphaFold 的核心团队:不再保留独立的 AlphaFold 团队,而是将相关研究人员分流至多个战略项目。这一调整被视为 DeepMind 将重心进一步转向 Gemini 大模型和 AI Agent 的重要信号。
来自主题: AI资讯
8757 点击 2026-07-30 10:02
 搜索
搜索
据英国《金融时报》7 月 29 日报道,谷歌 DeepMind 已经重组了曾打造诺贝尔奖级成果 AlphaFold 的核心团队:不再保留独立的 AlphaFold 团队,而是将相关研究人员分流至多个战略项目。这一调整被视为 DeepMind 将重心进一步转向 Gemini 大模型和 AI Agent 的重要信号。
最近,月之暗面 kimi 正式开源 Kimi K3 完整模型权重,Kimi K3 是一款总参数量达 2.8 万亿、上下文窗口达 100 万 token 的 MoE 大模型,更是全球首个落地的近 3 万亿参数级开源大模型,引起业界热议。
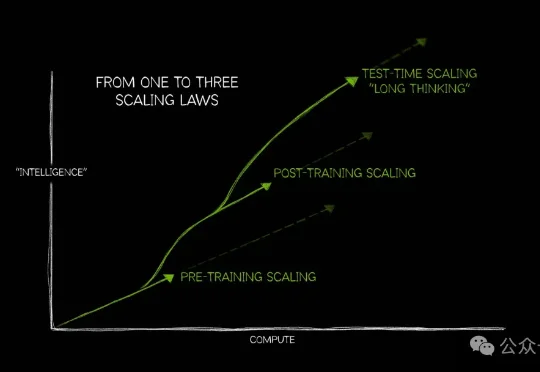
新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca
刚刚,网信中国发布公告,「Apple 智能」正式通过生成式人工智能服务备案。 和苹果一起「持证上岗」的还有华为小艺 AI 大模型、OPPO AndesGPT、vivo 蓝心端侧大模型、小米澎湃 AI、三星盖乐世 AI 和努比亚豆包手机大模型,一共 7 款手机端侧大模型在 7 月 8 日集体过审。

2026 年 6 月,HuggingFace 上一个名为 Boogu-Image-0.1 的开源模型,在上传以后迅速引爆了 AI 圈。这款模型最引人注目的地方,在于它以区区 10B 的参数规模,就在多项关键能力上超过了很多参数量更大的模型。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。
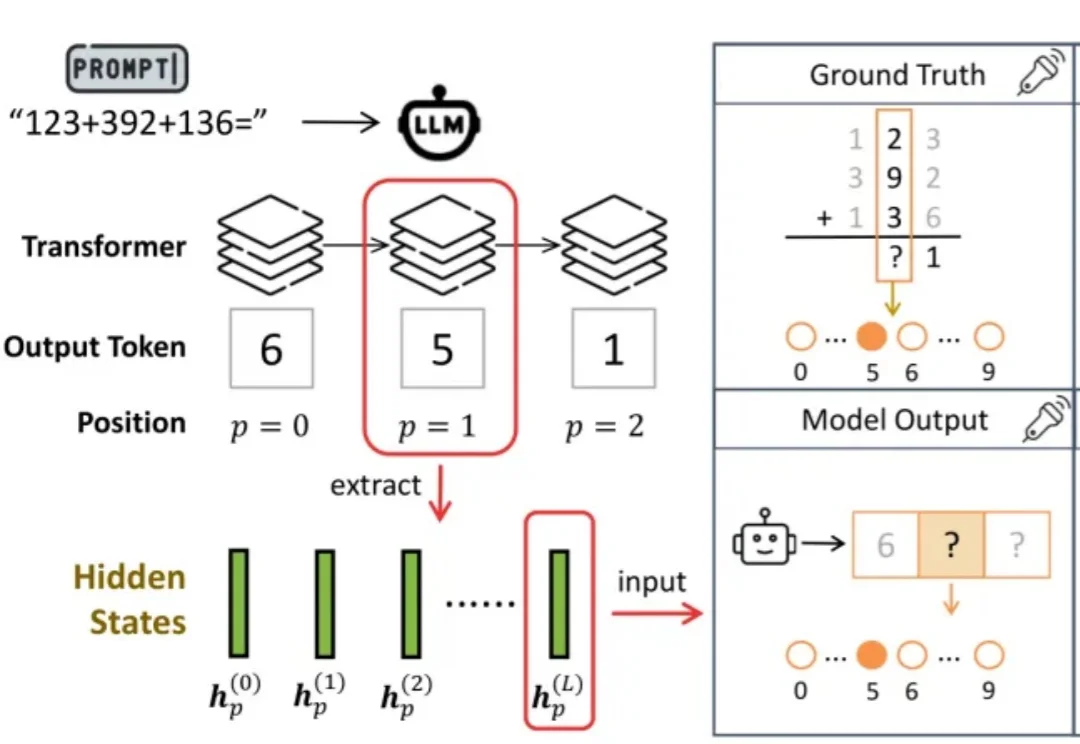
尽管大语言模型(Large Language Models, LLMs)在复杂数学推理、代码生成和知识问答上表现突出,但它们仍常在多位数加法这类基础算术任务上犯错。

在具身智能最难的泛化问题上,他们连续拿出顶会级成果,并把它们沉淀进其创新 VLOA 大模型,推动机器人迈向广阔现实。

你有没有想过,我们每天用的 AI 大模型,可能在某些词汇上天生就有缺陷?不是因为训练数据不够,不是因为算力不足,而是因为语言本身的规律——那些用得少的词,模型就是学不好。更让人意外的是,这个问题早在 2025 年就被一家中国创业公司系统性地发现并解决了。

姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。